New Features and Updates in V2025
Version 2025 of Luminata® adds new features including support for data entry from records in a Spectrus database and direct export to JSON format. There are also improvements to carryover calculations, data visualization, and an array of features for ease of use. Read below for details, and contact us for help upgrading your software.
Highlighted Features | Improved Features | Data Import & Export | Data Processing
Highlighted Features
Attach Data from Records in a Spectrus Database
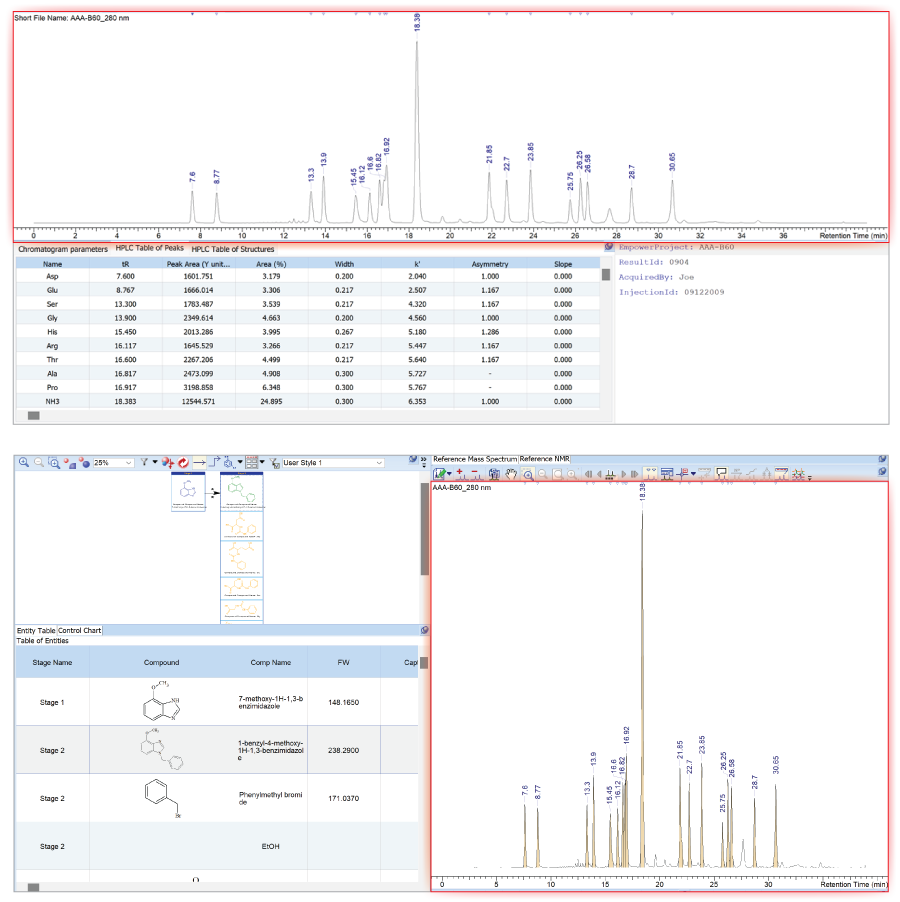
- You can now attach LC/UV/MS datasets and chromatograms, including peak names, from records in a Spectrus database to Luminata reaction records. Search and retrieve these datasets from within the Luminata interface using configurable metadata fields.
- This functionality bridges two platforms: Spectrus database as the analytical data management system and Luminata as the decision support tool for pharmaceutical development.
Direct Export to JSON Format
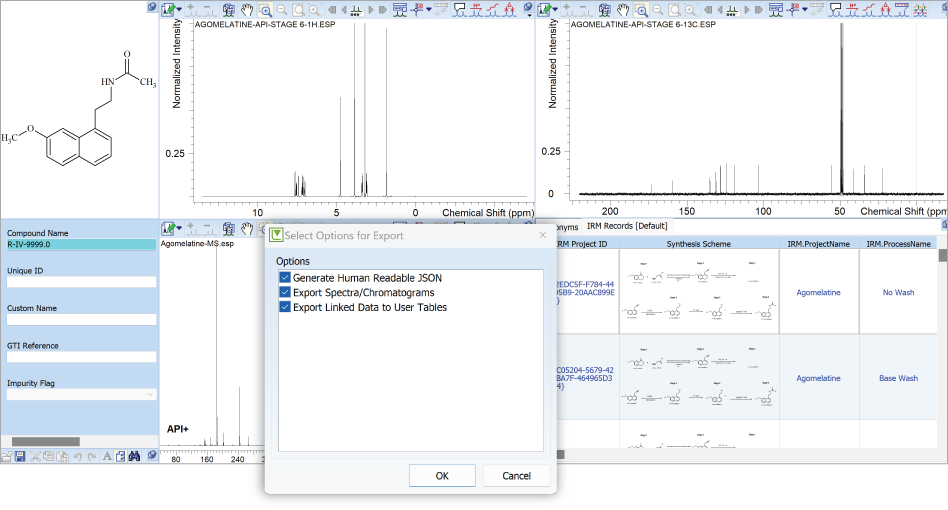
- You can now export compound record sets as JSON files directly from Luminata. The resulting file contains all contents of the record including user data, tables, notes, and chemical structures.
Improved Features
Data Analysis & Processing
Map a Broader Variety of Transformations
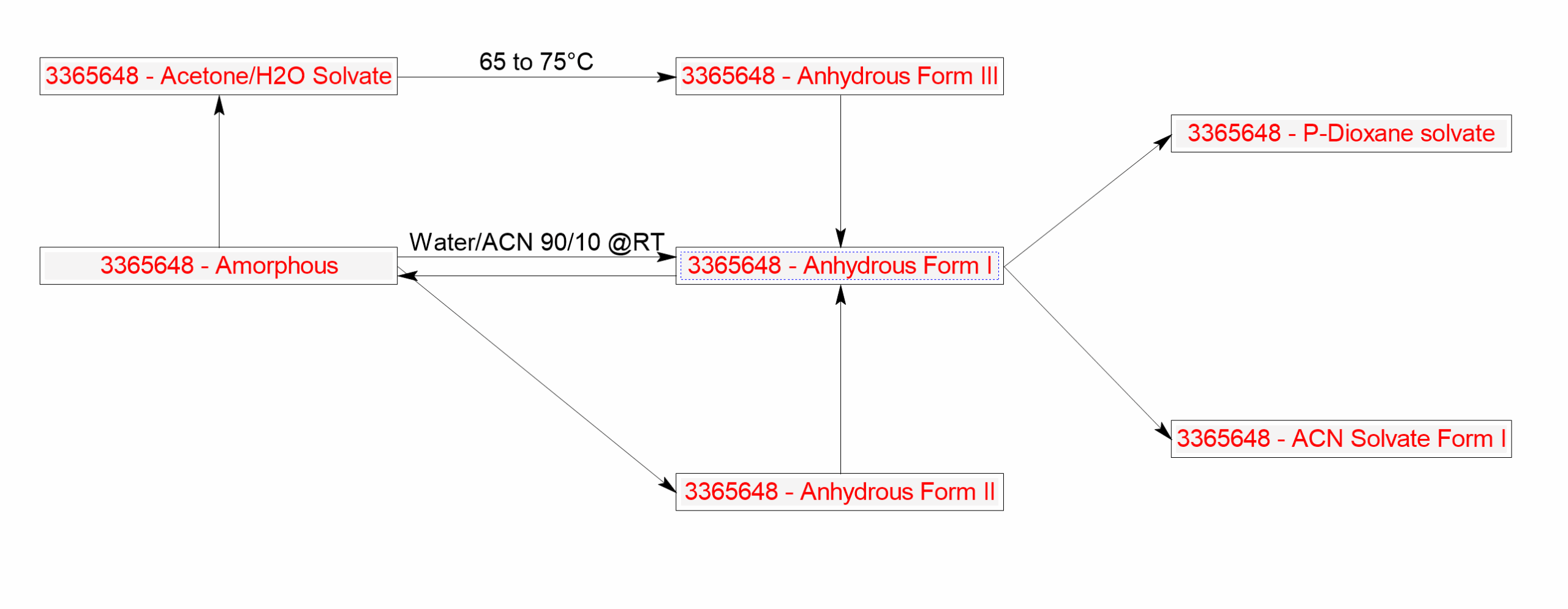
- You can now create transformation maps for more study types including solid form screenings. New features in the Batch Genealogy Map interface allow you to:
- Add distinct bidirectional arrows
- Display metadata fields above or below arrows
Calculate Incremental Cumulative Carryover
- You can now calculate the cumulative carryover at each stage in the process, known as the Incremental Cumulative Carryover. Previously you could only calculate the cumulative carryover over all stages.
- The incremental cumulative carryover for stage n is calculated as:
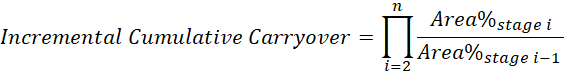
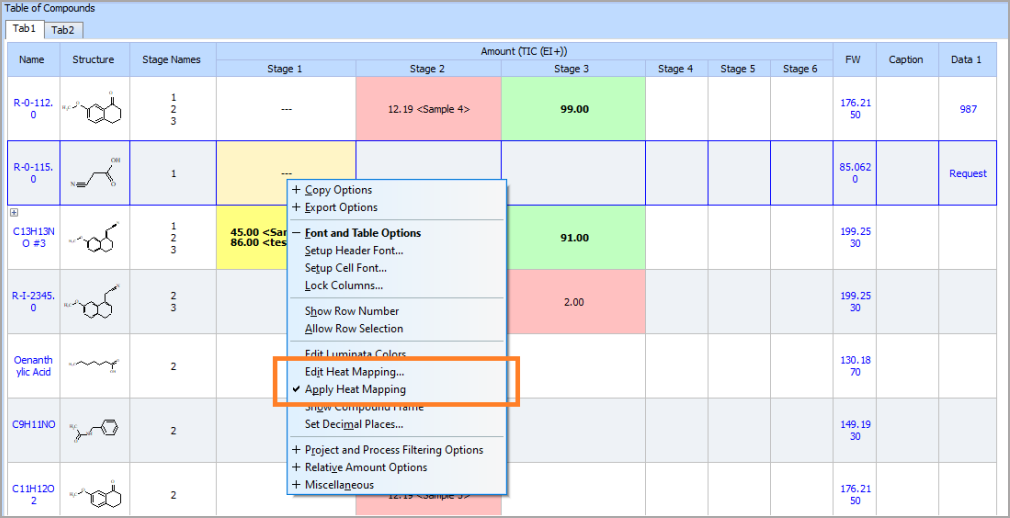
Visually Assess Variability with Color-Coded Heat Map of Impurity Levels
- You can now replace the randomized default colors in the columns of analytical results of the Control Chart with a customizable color-coded heat map to easily assess impurity level variability
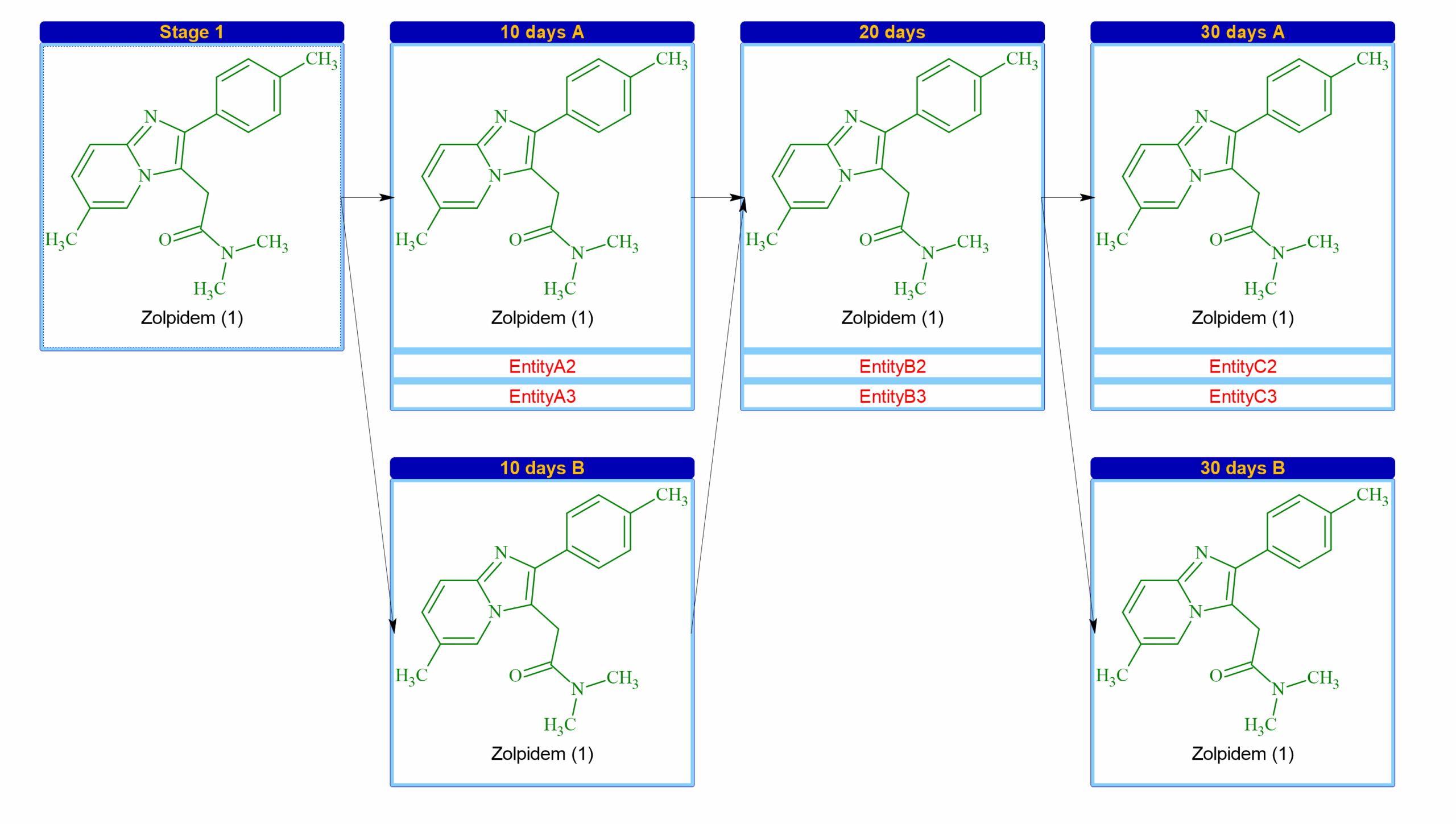
Create Non-Linear Project Maps
- You can now create more complex Project Maps for forced degradation and stability studies with the capability to create branching and converging steps
Databasing
Add Live iControl Trend Plots to Luminata Records
- You can now attach live trend plots from Mettler Toledo’s iControl directly to an existing Luminata record
Easier Database Navigation with Improved Organization
- You can now more easily find the records you need in the Database Navigation tree with more intuitively organized sub-levels
Ease of Use
- You can now quickly collapse or expand all the records contained within a node of a Project Map with the new +/- icons on each node
- You can now align and adjust stages, stage labels, and embedded objects in Batch Genealogy and Process Maps
- You now have the option to hide all branches in the project map except for the selected one
- You can now automatically populate the main compound across all stages when creating a Project Map of a forced degradation or stability study
- You can now create Carryover Snapshots for all impurities of a process stage simultaneously
- You can now customize the caption of a Carryover Snapshot when it is being created
- You can now reorder Carryover Snapshots in the record tree
- You now have the option to copy Carryover Snapshots to the new record when cloning applicable records
- You can now draw reactions more easily with the addition of 1700 structures and 13,000 names available to search in Dictionary, including common reagents and catalysts
- You can automatically revert back after showing all tabs of open data with the new Fit to Tab Names button
Improvements in Luminata JS
Luminata JS, formerly referred to as the Luminata web client, updates include new features to share results from any widget with a hyperlink and create custom tables. There are also improvements to database querying and handling of search results.
Create a URL Hyperlink to Share Results and Data
- You can now create a hyperlink from any widget to share data with other Luminata JS users. Hyperlinks to filtered tables retain their filtered state when opened.

Create a Custom Overview Table
- You can now create a custom table and choose the columns you wish to show and hide in the Project Overview widget
Get an Overview of the Metadata and Analytical Data of an Entire Project
- You can now view all metadata and see an overview of the analytical data of each reaction record within a project with the new Sample Mode in the Process Table
Filter Table Data Within Columns
- You can now filter data in a table by the values within a particular column. Filter by:
- Date (later than, earlier than, date range, exists)
- Numbers and Ranges (equal to, more than, less than, in range, exists)
- String (includes, exact, contains word, exists)
Improvements in Analytical Data Processing
As always, you can process data from various analytical techniques with Luminata. We’ve improved features for data processing, re-processing, and interpretation as well.
Processing MS & Chrom Data with Luminata
Data Analysis & Processing
Improved Peptide Fragmentation
You can now more easily interpret your spectra for complex linear and cyclic peptides.
- Fragment and label complex linear peptides as a, b, c, x, y, and z ions
- Generate fragment ions for cyclic peptides based on the Roepstorff-Fohlman-Biemann nomenclature
- Cyclic fragments are labelled using the anJK format where:
- a = type of peptide ion (e.g., a, b, x, or y)
- n = number of amino acid residues within the fragment
- J = residue at the N-terminus end of the cycle break
- K = residue at the opposite side of the cycle break
- Cyclic fragments are labelled using the anJK format where:
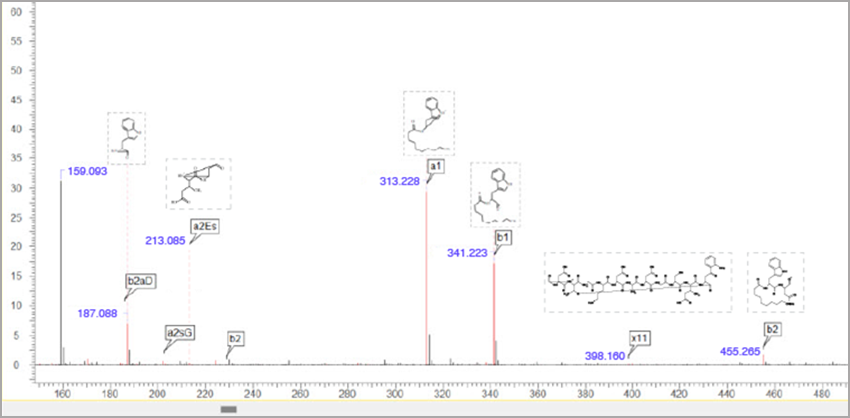
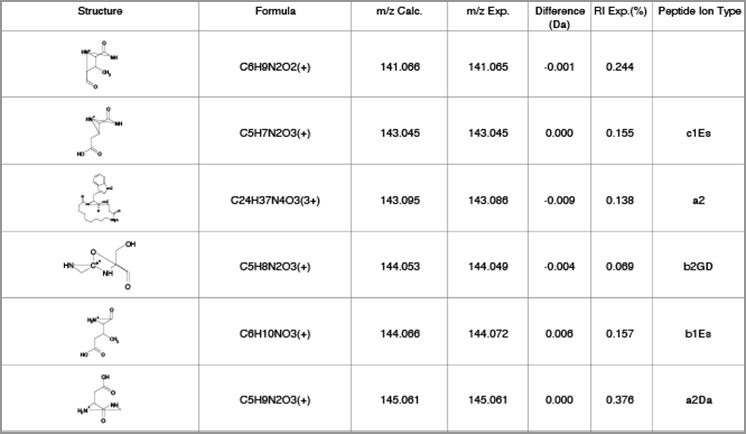
Mass spectrum and fragmentation table showing fragmentation of cyclic peptide and anJK peptide ion type.
Simplified User Input and Analysis
Improvements simplifying user input and analysis in quantitation have been made:
- Calculate and display the mean and %RSD for retention time and area in the calibration table for replicates
- You can now transfer the standard compound name to Table of Peaks
Better Efficiency in Intelligent Component Recognition Workflow (IXCR)
- You can use a dynamic mass range to reduce the spectral search criteria to 0.5 Da above the molecular ion which will also change your HQI score accordingly
- Automatically populate desired indices into the Table of Components when they exist in a searched database to more easily compare retention characteristics
Enhanced Data Analysis and Interpretation
Several improvements have been made to the IX, IXCR, and ITA algorithms, including:
- You can now control the conversion of spectra from a profile to centroid spectra (IX 2.0, IXCR)
- You can now interrogate your data further with automatic creation and display of MS3 Component spectra following processing (manual assignment, IX 2.0, IXCR, and ITA)
Simplified Chromatogram Peak Detection
- Filter your picked peaks by setting a minimum area threshold (as a percentage of the total) and automatically integrate all peaks above this limit
Improved Visualization of Chromatogram Structures
- You can adjust the size of structures displayed on peaks to better visualize those of interest
Reporting
Display Intensity Values on MS Peaks
- You can now view detector and relative intensity values directly over mass spectral peaks for easier analysis
Improved Visualization of Structures on Chromatograms
- You now have the ability to display chemical structures more clearly on chromatographic peaks in your reports
Updated Default MS Reports
- You now have more control over MS reports with the ability to generate improved default mass spectra reports
Expanded Component Reporting Options
- You can now report component mass spectra by collision energy, and include component UV spectra, giving you a more complete view of your data
Ease of Use
- You can now remove any unnamed components from the Table of Components with a single click
- You can now more easily set modifications to your mass spectra analysis with an improved Component Interpretation Options dialog box
- You can now display intensity values (detector or relative) over mass spectral peaks to more easily analyze your data
Processing NMR Data with Luminata
Data Analysis & Processing
Allow for Small Variations in the Integral Range of Peaks in External Standard qNMR
- You can now do external standard qNMR calculations using peaks whose integral ranges are not identical between replicates, which often occurs when working with manually defined integrals
New Parameters to Support Broader Workflows in External Standard qNMR
- You can now perform external standard qNMR calculations using replicate samples with different masses but constant volume with the help of:
- New parameters added to Concentration Calculation Tool and default report template
- Average w/w% (averaged across different replicates)
- w/w% RSD%
- Maximum Peak-to-Peak RSD% (intrasample)
- Mass and volume information included in the table of the Used Replicates popup menu
- New parameters added to Concentration Calculation Tool and default report template
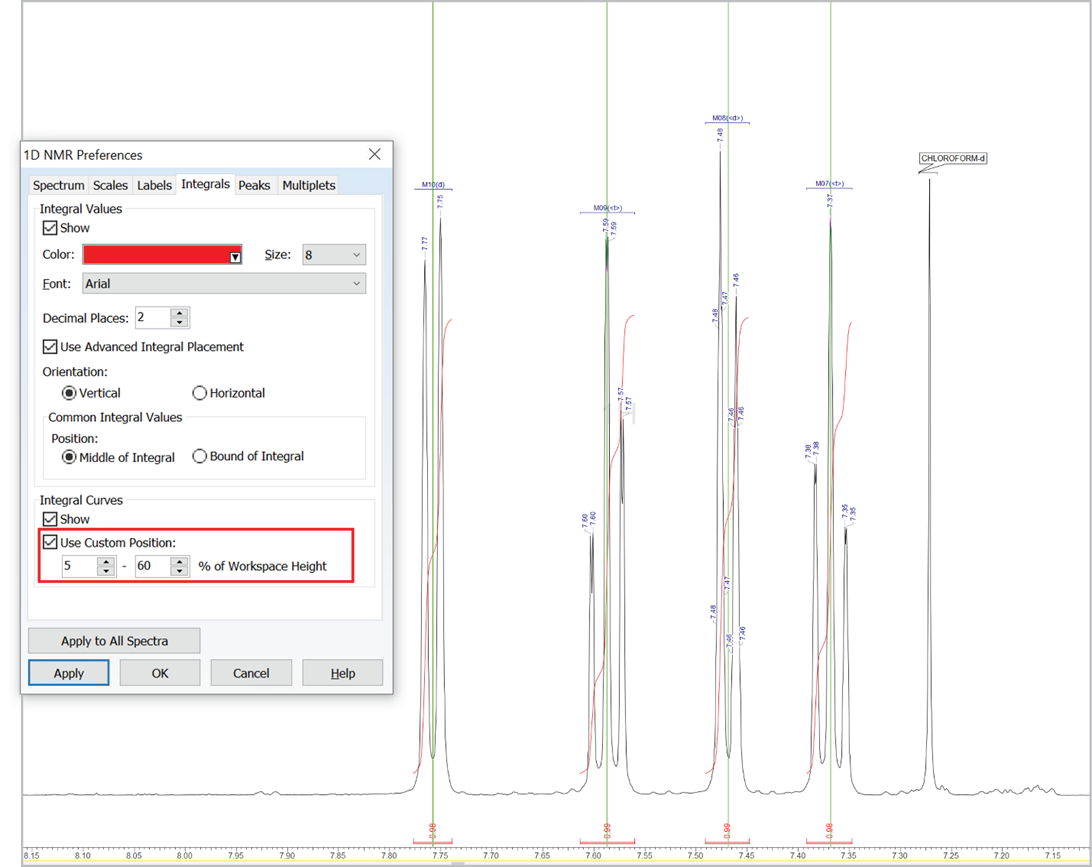
Customize the Position of Integral Curves
- You can now set a custom position for integral curves in the processing interface and reports by defining the desired vertical span of the highest curve in the displayed spectral region (as % relative to height of spectrum window, regardless of the vertical scale factor value)
Apply Unique Baseline Correction Parameters in Each Dimension of a 2D NMR Spectrum
- You can now apply baseline correction in each dimension of a 2D spectrum independently, allowing you to apply different parameters in each
Automatically Analyze Multiplets in 19F NMR Spectra
- You can now automatically analyze 19F spectra of structures with multiple fluorine atoms with an improved algorithm for better detection of first-order multiplet patterns
Improved Identification of Peaks Near Water in 1H NMR Spectra in DMSO
- You can now more accurately identify spectral peaks that appear at a similar position as the water peak in 1H spectra in deuterated DMSO (e.g., N-Me, O-Me, etc.) with an improved automatic analysis algorithm
User-Added Solvents/References Available to Macro Commands for NMR
- You can now utilize user-added solvents or references in macro commands by first invoking the new LoadSolventsTable macro command
Reporting
Optimize the Display of NMR Spectra in Reports
- You can now easily remove whitespace at the outer edges of frequency axes in 1D and 2D NMR spectra in reports. The new Auto Fit option in the Report Page Setup dialog box automatically selects a display region within ±0.5 ppm (¹H) or ±5 ppm (other nuclei) of the outermost peaks.
Summarize w/w% Values in qNMR Reports
- You can now include w/w% values for each replicate in the Sample Data table of a qNMR report
Ease of Use
- You can now quickly select/unselect all NMR integrals except for that of the solvent in external standard qNMR with new a context menu
Want to learn more?
Read more about the full features of Luminata, or contact us for help upgrading your software.